Kubernetes 采用的是基于扁平地址空间的网络模型,集群中的每个 Pod 都有自己的 IP 地址,Pod 之间不需要配置 NAT 就能直接通信。另外,同一个 Pod 中的容器共享 Pod 的 IP,能够通过 localhost 通信。
-
IP-per-Pod,每个 Pod 都拥有一个独立 IP 地址,Pod 内所有容器共享一个网络命名空间
-
集群内所有 Pod 都在一个直接连通的扁平网络中,可通过 IP 直接访问
- 所有容器之间无需 NAT 就可以直接互相访问
- 所有 Node 和所有容器之间无需 NAT 就可以直接互相访问
- 容器自己看到的 IP 跟其他容器看到的一样
接下来我们来先介绍一下几个概念,
- Service cluster IP 尽可在集群内部访问,外部请求需要通过 NodePort、LoadBalance 或者 Ingress 来访问
- 网络的命名空间:Linux在网络栈中引入网络命名空间,将独立的网络协议栈隔离到不同的命令空间中,彼此间无法通信;docker利用这一特性,实现不容器间的网络隔离。
- Veth设备对:Veth设备对的引入是为了实现在不同网络命名空间的通信。
- Iptables/Netfilter:Netfilter负责在内核中执行各种挂接的规则(过滤、修改、丢弃等),运行在内核 模式中;Iptables模式是在用户模式下运行的进程,负责协助维护内核中Netfilter的各种规则表;通过二者的配合来实现整个Linux网络协议栈中灵活的数据包处理机制。
- 网桥:网桥是一个二层网络设备,通过网桥可以将linux支持的不同的端口连接起来,并实现类似交换机那样的多对多的通信。
- 路由:Linux系统包含一个完整的路由功能,当IP层在处理数据发送或转发的时候,会使用路由表来决定发往哪里
如今,Kubernetes改变了软件开发的完成方式。作为用于管理容器化工作负载和服务的便携式,可扩展的开源平台,该平台可促进声明式配置和自动化,Kubernetes已证明自己是管理复杂微服务的主导者。它的受欢迎程度源于Kubernetes满足以下需求的事实:企业希望增长和减少支付,DevOps需要一个稳定的平台,可以大规模运行应用程序,开发人员想要可靠且可复制的流程来编写,测试和调试代码。这是一篇很好的文章,可以了解有关Kubernetes演化和架构的更多信息。
管理Kubernetes网络的重要领域之一是在内部和外部转发容器端口,以确保容器和Pod可以正确相互通信。为了管理此类通信,Kubernetes提供以下四种联网模型:
- 容器到容器通信
- 点对点通讯
- Pod到Service通讯
- 对外沟通
在本文中,我们通过向您展示Kubernetes网络中的Pod可以相互通信的方式,深入探讨Pod到Pod的通信。
虽然Kubernetes在如何部署和操作容器方面持固执己见,但对于如何设计运行Pod的网络来说,这并不是非常明确的规定。Kubernetes对任何网络实施都施加以下基本要求(除非有任何故意的网络分段策略):
- 所有Pod都可以与所有其他Pod通信,而无需NAT
- 所有运行Pod的节点都可以与所有Pod通信(反之亦然),而无需NAT
- Pod所看到的IP与其他Pod所看到的IP
为了说明这些要求,让我们使用具有两个群集节点的群集。节点位于子网192.168.1.0/24中,而Pod使用10.1.0.0/16子网,其中node1和node2分别将10.1.1.0/24和10.1.2.0/24用作Pod IP。
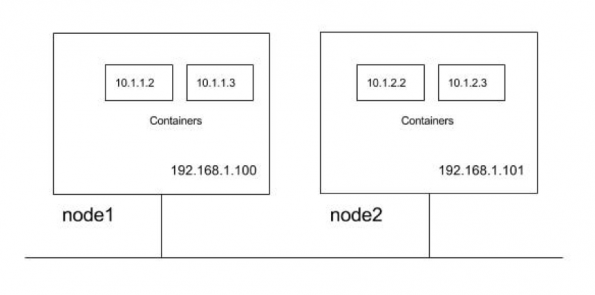
因此,从上面开始,网络必须建立遵循通信路径的Kubernetes要求。
- 节点应该能够与所有Pod通信。例如,192.168.1.100应该能够直接到达10.1.1.2、10.1.1.3、10.1.2.2和10.1.2.3(无NAT)
- Pod应该能够与所有节点通信。例如Pod 10.1.1.2应该能够在没有NAT的情况下达到192.168.1.100和192.168.1.101
- Pod应该能够与所有Pod通信。例如,10.1.1.2应该能够直接与10.1.1.3、10.1.2.2和10.1.2.3通信(无NAT)
在探索这些需求时,我们将为如何发现和公开服务奠定基础。可以通过多种方式设计满足Kubernetes网络要求的网络,并具有不同程度的复杂性和灵活性。
点对点网络和连通性
Kubernetes不会协调网络的建立,而是将作业卸载到CNI插件上。这是有关CNI插件安装的更多信息。以下是通过CNI插件实现的网络实现选项,这些选项允许Pod到Pod的通信满足Kubernetes的要求:
- 第2层(交换)解决方案
- 第三层(路由)解决方案
- 叠加解决方案
I-第2层解决方案
这是最简单的方法,适用于小型部署。Pod和节点应将Pod的IP子网视为一个单独的l2域。Pod到Pod的通信(在同一主机上或跨主机)通过ARP和L2交换进行。我们可以使用网桥 CNI插件在节点1(请注意/ 16子网)上进行以下配置,从而将L2网桥重用于pod容器。
{
"name": "mynet",
"type": "bridge",
"bridge": "kube-bridge",
"isDefaultGateway": true,
"ipam": {
"type": "host-local",
"subnet": "10.1.0.0/16"
}
}
需要预先创建kube-bridge,以便ARP数据包在物理接口上发出。为此,我们有另一个桥,该桥具有连接到其的物理接口和分配给它的节点IP,而kube-bridge通过如下所示的第ve对钩接到了该桥上。
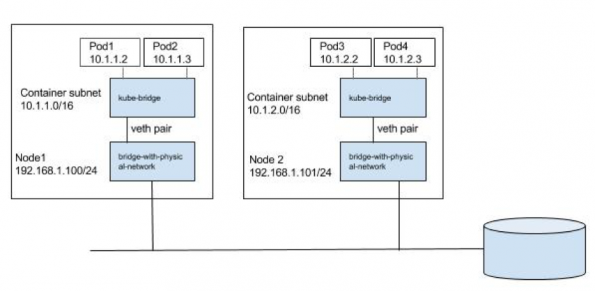
我们可以传递一个预先创建的桥,在这种情况下, 桥 CNI插件将重用该桥。
II-第3层解决方案
一种更具可扩展性的方法是使用节点路由,而不是将流量切换到Pod。我们可以使用网桥CNI插件为配置了网关的Pod容器创建网桥。例如,可以在下面的node1上使用配置(请注意/ 24子网)。
{
"name": "mynet",
"type": "bridge",
"bridge": "kube-bridge",
"isDefaultGateway": true,
"ipam": {
"type": "host-local",
"subnet": "10.1.0.0/24"
}
}
那么,在节点1上运行IP 10.1.1.2的Pod1如何与在节点2上运行IP 10.1.2.2的Pod3通信?我们需要节点将流量路由到其他节点Pod子网的方法。
我们可以使用子网路由填充默认网关路由器,如下图所示。到10.1.1.0/24和10.1.2.0/24的路由分别配置为通过node1和node2。当节点添加或删除到集群中时,我们可以自动使路由表保持更新。我们还可以使用一些可以在公共云上完成工作的容器联网解决方案,例如Flannel的AWS和GCE后端,Weave的AWS-VPC模式等。
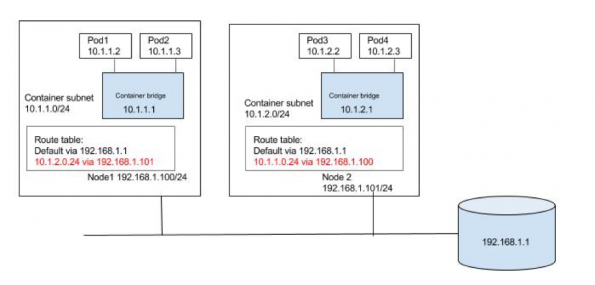
或者,可以如下图所示在每个节点上填充到其他子网的路由。同样,可以在小型/静态环境中自动更新路由,因为可以在群集中添加/删除节点,也可以使用容器网络解决方案(如calico)或Flannel主机网关后端。
III-叠加解决方案
除非有特殊原因使用覆盖解决方案,否则考虑到Kubernetes的网络模型通常是没有意义的,并且它缺乏对多个网络的支持。即使Pod位于覆盖网络中,Kubernetes要求节点应该能够到达每个Pod。同样,Pods也应该能够到达任何节点。我们将需要节点集中的主机路由,以便Pods和节点可以相互通信。由于主机间Pod到Pod的流量在底层结构中不可见,因此我们需要一个虚拟/逻辑网络,该网络覆盖在底层结构上。Pod到Pod的流量需要在源节点处封装。然后将封装的数据包转发到解封装的目标节点。可以围绕任何现有的Linux封装机制构建解决方案。我们需要有一个隧道接口(带有VXLAN,GRE等封装)和一个主机路由,以便通过隧道接口路由节点间Pod到Pod的流量。下面是关于如何构建可以满足Kubernetes网络要求的覆盖解决方案的非常概括的视图。与之前的两个解决方案不同,覆盖方法在建立隧道,填充FDB等方面花费了大量精力。现有的容器网络解决方案(如Weave和Flannel)可用于设置具有覆盖网络的Kubernetes部署。这是一篇很好的文章,可以阅读更多有关类似Kubernetes主题的内容。
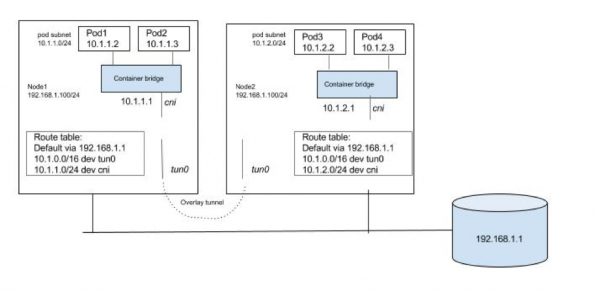
flannel
Flannel 是一个为 Kubernetes 提供 overlay network 的网络插件,它基于 Linux TUN/TAP,使用 UDP 封装 IP 包来创建 overlay 网络,并借助 etcd 维护网络的分配情况。
如何工作
Flannel 需要在集群中的每台主机上运行一个名为 flanneld 的代理程序,负责从预配置地址空间中为每台主机分配一个网段。Flannel 直接使用 Kubernetes API 或 ETCD 存储网络配置、分配的子网以及任何辅助数据(如主机的公网 IP)。数据包使用几种后端机制之一进行转发,包括 VXLAN 和各种云集成。

backend
Flannel 可以与几种不同的后端搭配。一旦后端设置完成,就不应在运行时更改。
VXLAN 是推荐的选择。对于有经验的用户,如果希望提高性能和基础架构支持(通常不能在云环境中使用),建议使用 host-gw。UDP 建议仅用于调试,或者用于不支持 VXLAN 的非常旧的内核。
另外,还有实验性的 AWS、GCE 和 AliVPC,所有支持的后端可以 参考这里。
VXLAN
使用内核的 VXLAN 封装数据包。 Type 和选项:
Type:字符串,vxlanVNI:数字,要使用的 VXLAN Identifier (VNI) 。默认是 1。Port:数字,用于发送封装的数据包 UDP 端口。默认值由内核决定,目前是 8472。GBP:布尔值,启用 基于 VXLAN 组的策略。默认是 false。DirectRouting:布尔值,当主机位于同一子网时,启用直接路由(类似 host-gw)。VXLAN 将仅用于将数据包封装到不同子网上的主机。默认为 false。
ip r
default via 192.168.12.1 dev enp0s3
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
192.168.12.0/24 dev enp0s3 proto kernel scope link src 192.168.12.102
host-gw
ip r
default via 192.168.12.1 dev enp0s3
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
192.168.12.0/24 dev enp0s3 proto kernel scope link src 192.168.12.102
default via 192.168.12.1 dev enp0s3
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
10.244.2.0/24 via 192.168.12.107 dev enp0s3
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
192.168.12.0/24 dev enp0s3 proto kernel scope link src 192.168.12.102
ip r
default via 192.168.12.1 dev enp0s3
10.244.0.0/24 via 192.168.12.102 dev enp0s3
10.244.2.0/24 dev cni0 proto kernel scope link src 10.244.2.1
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
192.168.12.0/24 dev enp0s3 proto kernel scope link src 192.168.12.107
cat /etc/cni/net.d/10-flannel.conflist
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
10: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default
link/ether 3e:99:d6:c1:e9:bb brd ff:ff:ff:ff:ff:ff
inet 10.244.0.0/32 scope global flannel.1
valid_lft forever preferred_lft forever
ip r
default via 192.168.12.1 dev enp0s3
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
192.168.12.0/24 dev enp0s3 proto kernel scope link src 192.168.12.102
host-gw
使用 host-gw 通过远程计算机 IP 创建到子网的 IP 路由。运行 flannel 的主机之间需要直接连接第 2 层(数据链路层)。(Use host-gw to create IP routes to subnets via remote machine IPs. Requires direct layer2 connectivity between hosts running flannel.) host-gw 性能好,依赖少,并且易于设置。 Type:
Type:字符串,host-gw下面对 host-gw 和 vxlan 这两种 backend 做个简单比较。
- host-gw 把每个主机都配置成网关,主机知道其他主机的 subnet 和转发地址。vxlan 则在主机间建立隧道,不同主机的容器都在一个大的网段内(比如 10.2.0.0/16)。
- 虽然 vxlan 与 host-gw 使用不同的机制建立主机之间连接,但对于容器则无需任何改变,bbox1 仍然可以与 bbox2 通信。
- 由于 vxlan 需要对数据进行额外打包和拆包,性能会稍逊于 host-gw。 host-gw只支持二层互通的网络
UDP
不可用于生产环境。仅在内核或网络无法使用 VXLAN 或 host-gw 时,用 UDP 进行 debug。 Type 和选项:
Type:字符串,udpPort:数字,用于发送封装数据包的 UDP 端口号,默认是 8285
Logging
- 从容器运行 flannel 时,将安装 Strongswan 工具。
swanctl可用于与 charon 交互,并提供日志命令.. - Charon 的日志也会写入 flannel 进程的标准输出。
Troubleshooting
ip xfrm state可以用来与内核的安全关联数据库进行交互。这可以用来显示当前安全关联(SA)以及主机是否成功建立到其他主机的 IPsec 连接。ip xfrm policy可以用来显示已安装的策略。Flannel 为每个连接的主机安装三个策略。 Flannel 不会恢复手动删除的策略(除非重新启动 Flannel)。它也不会在启动时删除陈旧的策略。可以通过重新启动主机或通过ip xfrm state flush && ip xfrm policy策略刷新和重新启动 flannel 来删除所有 ipsec 状态来删除它们。 Flannel 可以被添加到任何已经存在的 Kubernetes 集群中。但是在 Pod 使用网络之前添加 Flannel 是最简单的。 对于 Kubernetes v1.7+:
Ref
Kubernetes: Flannel networking
https://blog.laputa.io/kubernetes-flannel-networking-6a1cb1f8ec7c
kubernetes flannel代码解析
https://ieevee.com/tech/2017/08/12/k8s-flannel-src.html
GCE 理解k8s的网络 https://medium.com/google-cloud/understanding-kubernetes-networking-pods-7117dd28727
https://github.com/eranyanay/cni-from-scratch.git
https://superuser.openstack.org/articles/review-of-pod-to-pod-communications-in-kubernetes/